We have used:
- PostgreSQL@14 and pgAdmin4
Assumption of audience
It is assumed that you(the audience) have a moderate understanding of SQL language.
Introduction and Background
Understanding how to craft optimized SQL queries is essential for a proficient query developer. This article delves into various strategies for composing efficient queries, with a focus on their application in PostgreSQL databases. To illustrate these techniques, we will utilize two tables in our demonstration.
Table 1: department (
department_id serial primary key,
department_name varchar(255) not null
);
Table 2: employee_detail (
emp_id serial PRIMARY KEY,
emp_name VARCHAR(255) NOT NULL,
dob DATE not NULL,
department_id int,
foreign key(department_id) references department(department_id) on delete set NULL
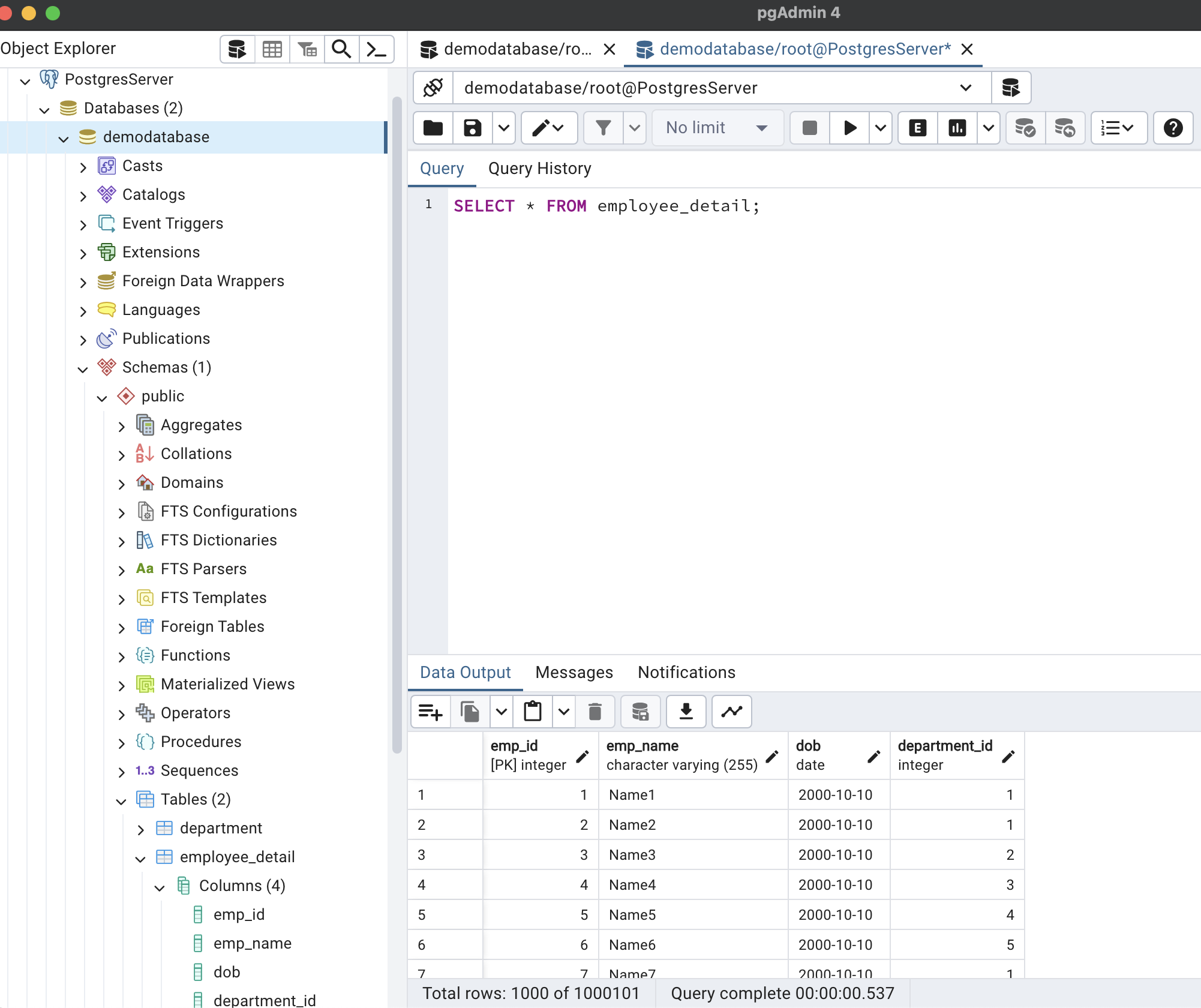
);The department table has 5 rows and the employee_detail has 1000101(one million one hundred and one) records. I added large records to see the effect on execution time. For demo purposes, we will be using pgAdmin 4 which also gives execution time.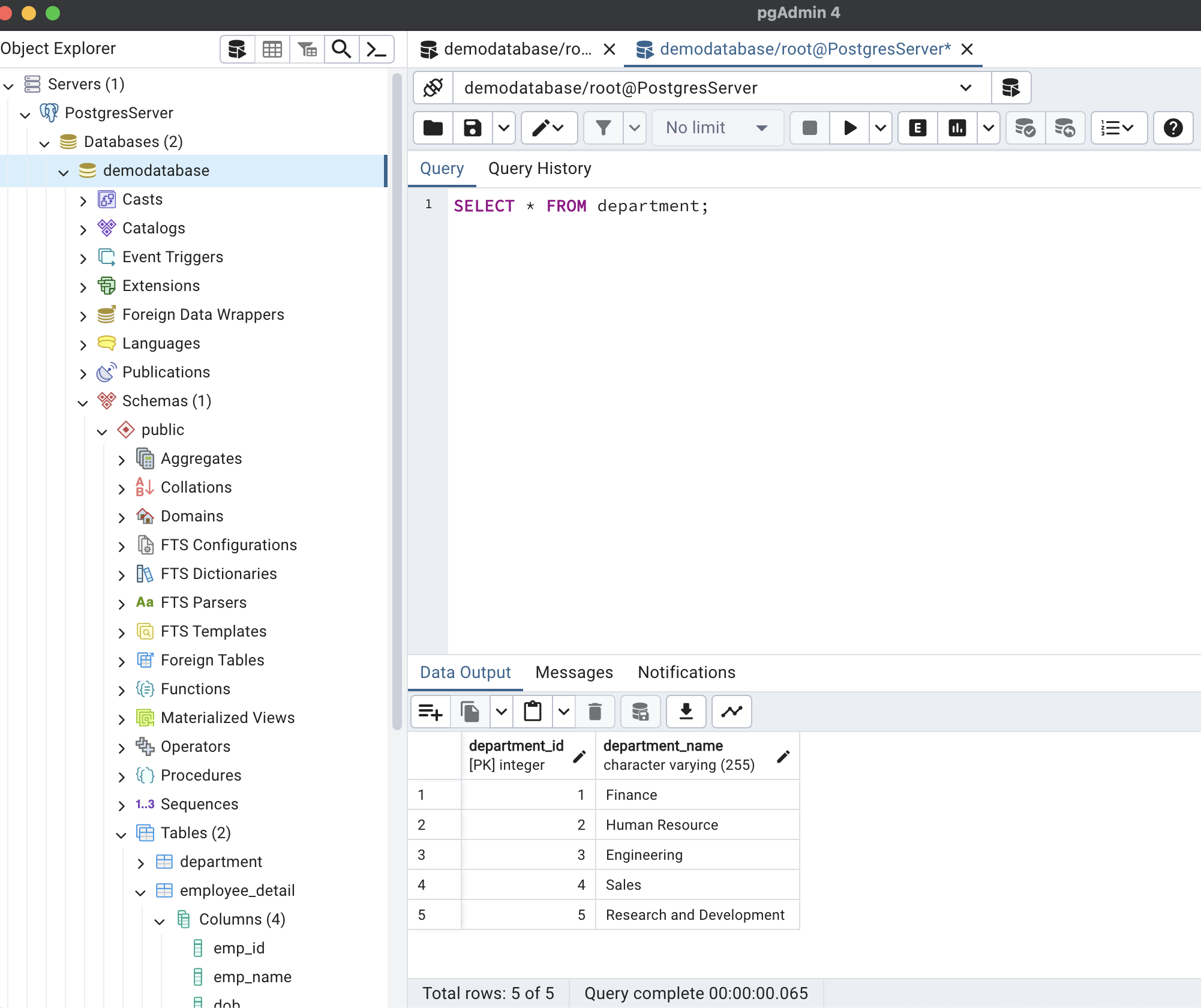
Tip 1: Writing Sargable Query
Sargable: A Sargable query short for “Search ARGument ABLE” is a query that can utilize the indexes in the database to optimize the query process. The Sargable query utilizes the argument that can take advantage of indexes(if it exists) to make the query faster.
Non-Sargable: A non-sargable query can not utilize the indexes even if it is present. The most common way to make a query non-sargable is to put the column inside a function in the where clause.
Let’s look at some of the examples:
Example1: Original query (Non-Sargable):
select * from employee_detail where extract('Year' from dob)=2000;Performance:Total query runtime: 861 msec and 970098 rows affected.
Improved query (Sargable):
SELECT * FROM employee_detail where dob >= '01-01-2000' and dob < '01-01-2001';Performance: Total query runtime: 541 msec and 970098 rows affected.
Example2: Original query (Non-Sargable):
select * from employee_detail where DATE_PART('year', current_date) - DATE_PART('year', dob) >= 30;Performance: Total query runtime: 206 msec. 10001 rows affected.
Improved query (Sargable):
select * from employee_detail where dob < current_date - INTERVAL '30 year';Performance: Total query runtime: 97 msec. 10001 rows affected.
Example3: Original query (Non-Sargable):
select * from employee_detail where coalesce(emp_name, 'Name22')='Name22';Performance: Total query runtime: 93 msec. 10001 rows affected.
Improved query (Sargable):
select * from employee_detail where emp_name='Name22' or emp_name is null;Performance: Total query runtime: 63 msec. 10001 rows affected.
Tip2: Using Indexes to improve performance.
The purpose of the indexes is to increase the query performance. Let’s look at a query before and after an index has been added.
Original Query:
select emp_name, dob from employee_detail where emp_name like 'Name%'; Before index performance:
Performance: Total query runtime: 354 msec. 1000101 rows affected.
After index performance:
Performance: Total query runtime: 337 msec.1000101 rows affected. Here due to indexing we can see that the performance has improved.
Tip 3: Use explicit column name in place of *
If you are extracting all the columns then use * in the select statement, however, if you want to pull only certain column use column names.
Pulling all the columns (* is better):
Select * from employee_detail;Performance: Total query runtime: 513 msec. 1000101 rows affected.
select emp_id, emp_name, dob, department_id from employee_detail; Performance: Total query runtime: 571 msec. 1000101 rows affected.
Here emp_id, emp_name, dob, and department_id are all the columns and we can see the * operation in this case performs better.
Pulling only some columns (column names is better)
select emp_name, dob from employee_detail; Performance: Total query runtime: 364 msec. 1000101 rows affected.
Here if we pull only emp_name and dob column we can see that the query time is much less compared to * operation
Tip 4: Use WHERE statement in place of HAVING:
In group by statement we are to use the HAVING clause for filtering, however, we can also use where before group by to first filter the data and then use group by for grouping.
Having said that, there are some conditions where HAVING is absolutely necessary, in those cases only using HAVING. For instance, the filter is by aggregating certain column values.
Original Query:
select count(emp_id) as emp_count, emp_name, dob from employee_detail
group by dob, emp_name
having emp_name like 'Name%';Performance: Total query runtime: 169 msec.101 rows affected.
Improved Query:
select count(emp_id) as emp_count, emp_name, dob from employee_detail
where emp_name like 'Name%'
group by dob, emp_name;Performance: Total query runtime: 140 msec. 101 rows affected.
Tip 5: Using join properly
Tip 5.1: Joining Big table to smaller one
While joining tables, putting the bigger table before the join statement makes the performance faster. Here, employee_detail is a larger table (one million + records) than department table(5 records).
Joining in pattern - big table - small table
select emp_name, dob, department_name from employee_detail
inner join department
on employee_detail.department_id = department.department_idPerformance: This below query took 478 msec; 1000101 rows affected.
Joining in pattern - small table - big table
select emp_name, dob, department_name from department
inner join employee_detail
on employee_detail.department_id = department.department_idPerformance: Total query runtime: 494 msec.1000101 rows affected.
Both the above query do the same thing and only the order here is changed. If we know which one is a big table and which one is smaller, putting a big table in front of the join statement can improve performance.
Tip 5.2 Avoid using multiple OR statements in a join statement
If you have two or more OR statements in the ON operator, using a single operator for joining and making multiple queries which are joined by union all would provide better performance.
Example:
select column1, column2, columnN table1 t1
inner join table2 t2
on t1.column1=t2.column1 OR t1.column2 = t2.column2This can be broken down into
select column1, column2, columnN table1 t1
inner join table2 t2
on t1.column1=t2.column1
UNION ALL
select column1, column2, columnN table1 t1
inner join table2 t2
on t1.column2 = t2.column2Tip 6: Replacing multiple OR statement with IN
If you are using multiple OR statements to filter out data, comparing those values using IN statements is much more efficient.
Original Query:
select emp_id from employee_detail where emp_name = 'Name11' or emp_name = 'Name22' or emp_name='Name33';Performance: Total query runtime: 94 msec. 30003 rows affected.
Improved Query:
select emp_id from employee_detail where emp_name in ('Name11', 'Name22','Name33');Performance: Total query runtime: 91 msec. 30003 rows affected.
Tip 7: Using UNION ALL Over UNION
The union all and union both are used to combine results from two or more queries. The UNION ALL combines data as it is, without filtering for distinct elements. The UNION combines data and also filters for unique values so that the combined result will have only distinct items.
Both of these are doing separate tasks one is just combining and another is combining as well as filtering for distinct items. We can not compare them if they are providing different outputs. However, if in case we know that 2 result sets are unique to each other then using UNION ALL in place of UNION will improve query performance.
Let’s check by combining result from same table:
select emp_name, dob from employee_detail
UNION ALL
select emp_name, dob from employee_detailPerformance: Total query runtime: 649 msec.2000202 rows affected.
select emp_name, dob from employee_detail
UNION
select emp_name, dob from employee_detailPerformance: Total query runtime: 1 secs 24 msec.101 rows affected.
Here we can see that the outputs are completely different numbers of rows, however, the key point is since the UNION is also performing filtering operations it takes more time.
Tip 8: Using LIMIT to extract data
Most of the time, we see data in parts, not all at once. It’s like flipping through pages. Only when there’s not too much data does it show up all together. That’s when using LIMIT comes in handy, saving us time by grabbing just the right amount we need.
Original Query:
select emp_name, dob from employee_detail; Performance: Total query runtime: 364 msec. 1000101 rows affected.
Improved Query:
select emp_name, dob from employee_detail LIMIT 50;Performance: Total query runtime: 65 msec. 50 rows affected.
Conclusion
In this article, we looked at some of the ways to make SQL query better. These are some techniques, there are still more techniques based on optimizing subqueries, improving through partition and sharding, and utilizing stored procedures for optimizing SQL queries which we will examine in future articles.